판별자 네트워크
판별자 네트워크는 DCGAN과 마찬가지로 스트라이드가 2인 합성곱층으로 구성되어 있습니다. 하지만 뒤의 두 계층은 스트라이드가 1인 밸리드 합성곱(valid convolutional)8을 이용하여 최종적으로 30×30 형태의 데이터를 출력합니다. 일반적인 GAN 모델의 출력이 0~1 사이의 스칼라인 것과는 차이가 있는데, 출력에서 차이가 있는 이유는 판별자를 이미지의 각 부분별로 진행하기 위해서입니다. 즉, 이미지를 통째로 진짜인지 아닌지 판별하는 것이 아니라 이미지의 각 부분이 진짜인지 아닌지 판별하기 위해서입니다. 이 과정에 따라 좀 더 디테일한 부분에 집중한 이미지를 판별할 수 있습니다.
또한, PIX2PIX의 훈련을 위한 손실 함수는 다음과 같습니다.
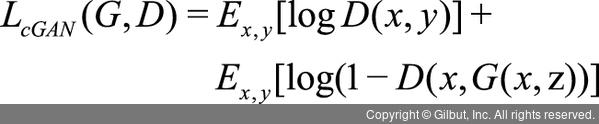
이때 생성자는 판별자를 속이는 것 말고도 생성한 이미지가 정답(입력 이미지)과 같아야 하는 과제가 있습니다. 이를 위해 PIX2PIX에서는 L1 손실 함수(L1 loss)9를 사용하며 수식은 다음과 같습니다.
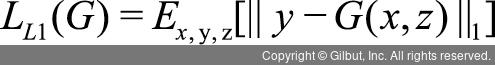
따라서 L1 손실 함수가 추가된 최종 손실 함수는 다음과 같이 수정하여 사용됩니다.
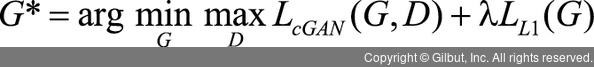
8 합성곱층에 패딩을 적용하지 않은 것입니다.
9 실제 값과 예측 값 사이의 차이(오차) 값에 대한 절댓값을 구하고, 그 오차들의 합을 L1 손실이라고 합니다.