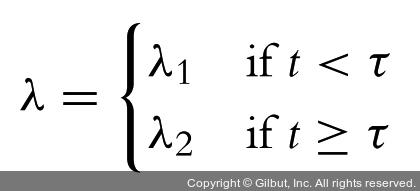
만약 현실에서 어떤 변화가 일어나지 않았고, λ1 = λ2라면 λ의 사후확률분포는 거의 같다고 봐야 한다.
우리는 알려지지 않은 λ를 추론하고 싶다. 베이지안 추론을 사용하려면 λ의 여러 가능한 값에 사전확률을 할당해야 한다. λ1과 λ2에 대한 바람직한 사전확률분포는 무엇인가? λ는 임의의 양수여야 한다는 점을 상기하자. 앞서 본 것처럼 지수분포는 양수에 대해 연속밀도함수를 제공하므로 λi를 모델링하기에 적합한 선택일 수 있다. 그러나 지수분포는 그 자체의 모수를 가지고 있다는 점을 상기하자. 따라서 우리는 모델에 그 모수를 포함시켜야 한다. 그 모수를 α라고 하자.

α는 초모수(hyperparameter) 또는 부모변수(parent variable)라고 한다. 말 그대로 다른 모수에 영향을 주는 모수다. α에 대한 초기 추측이 모델에 크게 영향을 미치지 않아 우리는 어느 정도 유연성 있는 선택을 할 수 있다. 우리는 모델에서 이 모수 α를 지나치게 고집하지 않는다. 나는 α를 개수 데이터 평균의 역수가 되도록 설정할 것을 제안한다. 왜냐하면 우리는 지수분포를 사용해 λ를 모델링하기 때문이다. 앞서 보여준 기댓값을 사용하여 다음과 같은 식을 얻을 수 있다.
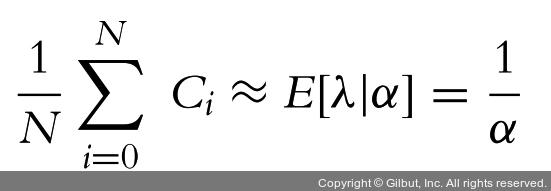
이 값을 사용함으로써 사전확률을 너무 고집하지 않고, 초모수의 영향력을 최소화한다. 내가 여러분에게 권하는 대안은 λi마다 하나씩, 사전확률을 두 개 갖는 것이다. 다른 λi 값을 가진 지수분포 두 개를 만드는 것은 관측기간 중 어느 시점에서 비율이 변했다는 우리의 사전 믿음을 반영하는 것이다.