8.3 클러스터링 모델
앞에서 설명한 대로 클러스터링의 목적은 데이터를 세분화하여 특정 그룹으로 묶는 것이다. 다양한 클러스터링 알고리즘이 있으며, 모든 클러스터 사이의 공통분모는 개체의 그룹을 찾는 것이다.
예를 들어 모델링에 다변량 분포를 사용하는 분포 모델이 있다. 그래프 모델은 그림 8-2와 같이 노드가 메인 에지에 연결된 작은 부분 집합(subset)을 표시할 때 클러스터 같은 속성을 보인다.
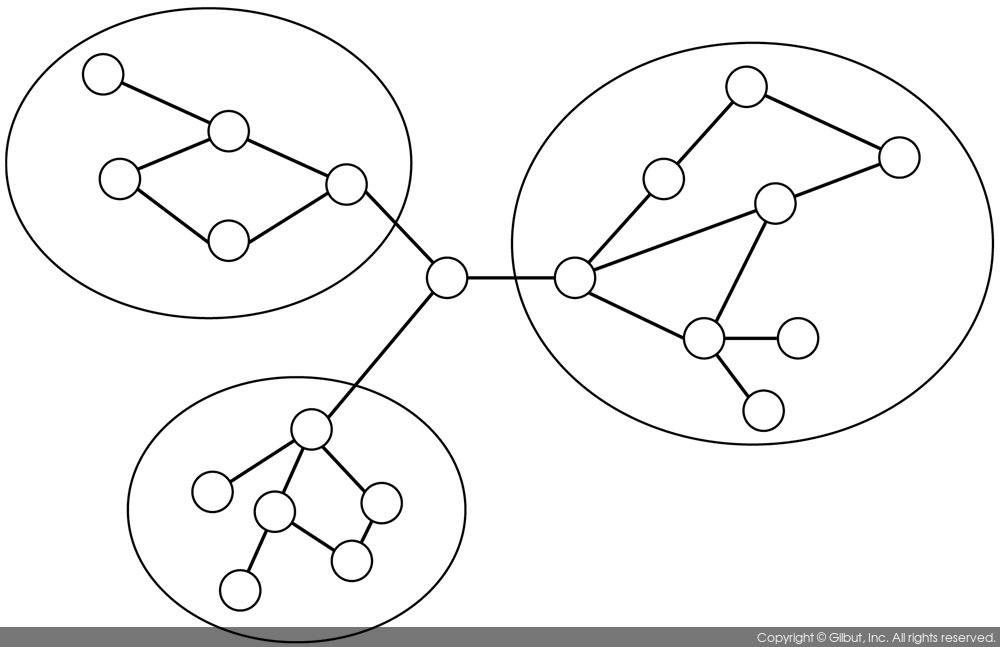
▲ 그림 8-2 클러스터로서 노드와 에지
물론 구조화된 쿼리로 그룹을 짓는 방식대로 소규모의 클러스터링을 시도할 수도 있다.
가장 흔히 사용되는 클러스터 모델은 중심 모델(centroid model)로, k-means 알고리즘이 들어간다. k-means 알고리즘은 기본적으로 벡터 양자화(vector quantization)다. 이 장에서는 k-means 알고리즘을 집중 설명하여 후반부 실습에 필요한 기본 토대를 만들 것이다.