3.5.1 유사도 정의
유사도가 무엇을 의미하는지는 정하기 나름입니다. 사례 페어 간 유사도는 거리를 계산해서 정의할 수 있습니다. 유사도 = 거리(사례_1, 사례_2). 그러고 나면, 유사도에 대한 아이디어는 거리를 계산하는 방법으로 인코딩됩니다. 비슷한 것들은 서로 가까이 있게 됩니다. 이질적인 것들은 서로에게서 멀리 떨어집니다.
두 사례의 유사도를 계산하는 세 가지 방법에 대해 알아봅시다. 유클리드 거리는 고등학교 기하학이나 삼각 함수로 거슬러 올라갑니다. 우리는 두 사례를 공간상의 점들로 취급합니다. 두 점을 이으면 하나의 직선이 됩니다. 그은 직선을 직각삼각형의 빗변으로 두고 피타고라스의 정리를 적용하여 삼각형의 나머지 두 변을 이용해서 거리를 구합니다(그림 3-4). c2 = a2 + b2이나 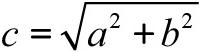 공식이 기억나나요? 너무 걱정하지 마세요. 이것을 직접 계산할 필요는 없습니다. scikit-learn에 “대신 해 줘.”라고 할 수 있거든요. 지금쯤이면 여러분은 다음에는 어떤 더 어려운 문제가 나올지 신경 쓰일 것이에요. 음, 솔직히 이야기하자면 더 어려운 내용이 나옵니다. 민코프스키 거리는 아인슈타인과 그의 상대성 이론까지 이어지니까요. 그렇지만 그 블랙홀에 빠지지 않도록 주의합시다.
공식이 기억나나요? 너무 걱정하지 마세요. 이것을 직접 계산할 필요는 없습니다. scikit-learn에 “대신 해 줘.”라고 할 수 있거든요. 지금쯤이면 여러분은 다음에는 어떤 더 어려운 문제가 나올지 신경 쓰일 것이에요. 음, 솔직히 이야기하자면 더 어려운 내용이 나옵니다. 민코프스키 거리는 아인슈타인과 그의 상대성 이론까지 이어지니까요. 그렇지만 그 블랙홀에 빠지지 않도록 주의합시다.
그 대신 간단한 예, 아니요 혹은 참, 거짓으로 구성된 특성을 가진 사례가 있을 때는 거리를 재는 또 다른 방법이 있습니다. 불(Boolean) 데이터에는 특성이 다른 횟수를 세는 것으로 두 사례를 멋지게 비교할 수 있습니다. 이 간단하고도 똑똑한 아이디어는 해밍(hamming) 거리라는 이름도 있습니다. 해밍 거리는 정확도(accuracy)의 가까운 사촌이나 형제 혹은 쌍둥이 동생처럼 보일지도 모르겠습니다. 정확도는 타깃과 같은 답의 비율, 즉 정답의 비율로,  으로 계산합니다. 해밍 거리의 총합은 다른 값의 개수입니다. 두 답안지 세트가 서로 완벽히 일치한다면 정확도는 100%로 높아져야 합니다. 두 특성 세트가 서로 동일하다면, 그들 간의 유사도 거리도 0으로 낮아져야 합니다.
으로 계산합니다. 해밍 거리의 총합은 다른 값의 개수입니다. 두 답안지 세트가 서로 완벽히 일치한다면 정확도는 100%로 높아져야 합니다. 두 특성 세트가 서로 동일하다면, 그들 간의 유사도 거리도 0으로 낮아져야 합니다.