4.3.3 선형 회귀
지금까지 하나의 특성 x만 사용하여 어떤 일이 일어나는지 알아보았습니다. 더 많은 특성을 모델에 추가하면, 즉 열과 차원이 늘어나면 어떻게 될까요? 하나의 기울기 m이 아니라 특성별로 기울기를 다루어야 합니다. 각 입력 특성이 결과에 각각 영향을 주게 됩니다. 특성 하나가 결과에 어떤 영향을 주는지 배운 것처럼, 이제는 여러 특성에서 얻게 되는 상대적인 영향력을 다루어야 합니다.
특성별로 기울기를 추적해야 하기 때문에 m이 아닌 가중치(weights)로 각 특성의 영향력을 표현합니다. 2.5절에서 했던 것처럼 예측을 수행하기 위해서는 가중치와 특성을 이용하여 선형 결합을 만듭니다. 요점은 예측 결과는 rdot(weights_wo, features) + wgt_b라는 것입니다. weights_wo가 b를 포함하지 않는다면 말이죠. weights의 0번째 값으로 b를 넣고, features_p1에 값이 1인 열을 하나 추가하면 수식을 rdot(weights, features_p1)로도 쓸 수 있습니다. 오차는 distance(prediction, actual)이며, 예측 값은 prediction = rdot(weights, features_p1)입니다. 점곱을 이용한 수식은 다음과 같습니다.
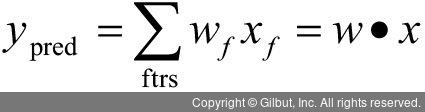
In [17]:
lr = linear_model.LinearRegression()
fit = lr.fit(diabetes_train_ftrs, diabetes_train_tgt)
preds = fit.predict(diabetes_test_ftrs)
# 따로 떼어 둔 테스트 타깃으로 예측 성능을 평가합니다
metrics.mean_squared_error(diabetes_test_tgt, preds)
Out [17]:
2848.2953079329427
mean_squared_error는 잠시 후에 다시 살펴보겠습니다. 사실 여러분은 이미 그 개념을 이해하고 있습니다. MSE는 예측 오차의 평균 거리입니다.