5.4.2 비용
과대적합에서 보았듯이, 모델을 복잡하게 만들면 아무리 노이즈가 심하더라도 패턴을 외울 수 있습니다. 그렇기 때문에 과도한 복잡성을 지양하고 단순함을 지향해야 하지요. 이를 위해 훈련 오차에 어떤 값을 더해 비용 개념을 만들었습니다. 개념적으로 비용은 손실과 복잡성의 합이지만, 몇 가지 추가할 것이 있습니다. 복잡도를 다루기 위해 추가하는 항목은 여러 가지 기술적 명칭으로 부릅니다. 정규화(regularization), 평활화(smoothing), 벌칙화(penalization), 홀쭉화(shrinkage) 등이 있지만, 복잡도라고 하겠습니다. 요약하자면, 어떤 데이터에 모델을 사용하기 위해 내는 전체 비용은 (1) 모델이 얼마나 잘 동작하는지와 (2) 모델이 얼마나 복잡한지에 달려 있습니다. 여기에서 복잡도 부분은 기본 투자라고 생각하면 됩니다. 초기 투자 규모가 크다면 오차가 적어야 좋을 것입니다. 반대로 초기 투자 규모가 작다면, 오차가 어느 정도 있어도 괜찮습니다. 이것은 모두 우리가 아직 보지 못한 새로운 데이터에서 좋은 성능을 얻고 싶기 때문입니다. 미지의 데이터 성능을 의미하는 용어가 일반화(generalization)입니다.
마지막 코멘트입니다. 오차와 복잡도의 상충 관계를 다루는 방법에 고정관념을 가질 필요는 없습니다. 정해진 답이 없습니다. 어느 쪽에 가중치를 더 두느냐는 우리 선택에 달렸습니다. 기술적인 용어로 말하자면, 또 하나의 하이퍼파라미터인 셈입니다. 수식에서는 그리스 소문자인 람다 λ를 사용합니다. 람다는 상충 관계를 표현합니다. 손실과 복잡도만으로 학습 모델을 규정하는 것은 조금 부자연스럽습니다. 이것은 15장에서 더 이야기하겠습니다. 가장 좋은 λ는 어떻게 찾을 수 있을까요? 여러 번의 검증 테스트를 거쳐 가장 낮은 비용을 기록한 λ를 고르면 됩니다.
In [15]:
def complexity(model): return model.complexity def cost(model, training_data, loss, _lambda): return training_loss(m,D) + _lambda * complexity(m)
수식으로는 다음과 같이 표현할 수 있습니다.
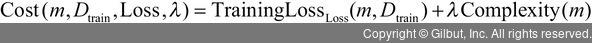
즉, (1) 더 많은 실수를 하거나 (2) 모델이 더 비싸고 표현력이 강해질수록 비용이 증가합니다. λ를 2로 설정하면, 복잡도 1단위는 손실 2단위에 대응됩니다. λ가 .5라면, 복잡도 2단위는 손실 1단위에 대응됩니다. λ를 이용해서 오차와 복잡도의 중요도를 조정할 수 있습니다.