5.5.4 더 나은 길과 뒤섞기
훈련-테스트 분리를 여러 번 실행하기 위해 반복문을 관리하는 것은 조금 짜증이 납니다. 엄청 어렵거나 힘든 일은 아니지만 실수할 구석이 많지요. 누가 깔끔하게 독립된 코드로 묶어 두면 참 좋을 텐데 말이죠. 다행히도 sklearn이 그것을 해 두었습니다. ShuffleSplit 데이터-분리기를 cross_val_score의 cv 인자로 전달하면 앞서 작성한 알고리즘을 그대로 사용할 수 있습니다.
In [25]:
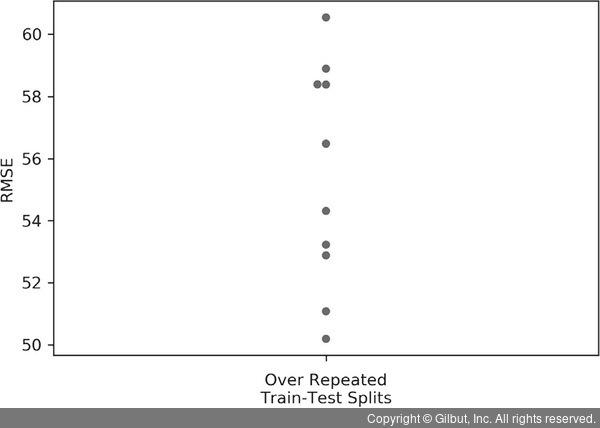
linreg = linear_model.LinearRegression() diabetes = datasets.load_diabetes() # cv 인자로 ss를 전달합니다 ss = skms.ShuffleSplit(test_size=.25) # 기본 n_splits=10 scores = skms.cross_val_score(linreg, diabetes.data, diabetes.target, cv=ss, scoring='neg_mean_squared_error') scores = pd.Series(np.sqrt(-scores)) df = pd.DataFrame({'RMSE':scores}) df.index.name = 'Repeat' display(df.describe().T) ax = sns.swarmplot(y='RMSE', data=df) ax.set_xlabel('Over Repeated\nTrain-Test Splits');
|
count |
mean |
std |
min |
25% |
50% |
75% |
max |
|
|
RMSE |
10.000 |
55.439 |
3.587 |
50.190 |
52.966 |
55.397 |
58.391 |
60.543 |