5.8 교차 검증으로 학습 모델 비교
교차 검증의 이점은 여러 가지 학습 세트로 성능이 어떻게 달라지는지 볼 수 있다는 것입니다. 그렇게 하려면 각 평가의 결과를 따로 저장해서 서로 비교해야 합니다. 즉, 각 폴드의 결과를 따로 분리해서 그래프에 표시해야 합니다. 간단한 그래프로 그려 보면 다음과 같습니다.
In [38]
classifiers = {'gnb' : naive_bayes.GaussianNB(), '5-NN' : neighbors.KNeighborsClassifier(n_neighbors=5)}
iris = datasets.load_iris()
fig, ax = plt.subplots(figsize=(6, 4))
for name, model in classifiers.items():
cv_scores = skms.cross_val_score(model, iris.data, iris.target, cv=10, scoring='accuracy', n_jobs=-1) # 코어를 모두 사용합니다
my_lbl = "{} {:.3f}".format(name, cv_scores.mean())
ax.plot(cv_scores, '-o', label=my_lbl)
ax.set_ylim(0.0, 1.1)
ax.set_xlabel('Fold')
ax.set_ylabel('Accuracy')
ax.legend(ncol=2);
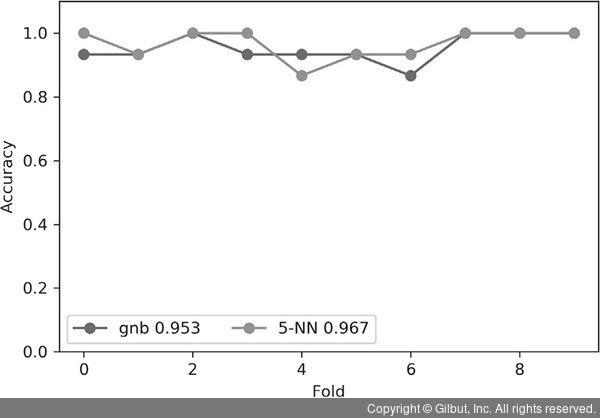
비슷한 결과가 많이 나왔습니다. 5-NN은 세 번 이겼지만, GNB는 한 번밖에 이기지 못했습니다. 다른 폴드에서는 성능이 엇비슷합니다. 이렇게 ‘누가 더 나은지’ 비교하는 것은 stripplot이나 평균 계산으로는 어려웠을 것입니다. stripplot에서는 폴드를 구분할 수 없고, 평균은 개별 폴드 값을 압축해 버리기 때문이지요.