5.6.5 편향- 분산 상충 관계의 예시
편향-분산 상충 관계의 구체적인 예시를 k-NN, 선형 회귀와 나이브 베이즈로 알아보겠습니다.
k-NN의 편향- 분산
이웃의 수가 달라지면 k-NN에 어떤 일이 일어나는지 생각해 봅시다. 먼저 극단적인 값을 넣어 볼까요? 가장 적은 이웃의 수는 1입니다. 즉, “나와 가장 비슷한 이웃을 찾아 그 타깃을 사용한다.”라는 의미입니다. 1-NN은 아주 들쭉날쭉하고 구불구불한 경계면을 가질 확률이 높습니다. 모든 개별 학습 사례가 예측에 절대적인 영향력을 행사합니다. 다른 이웃 의견은 들을 필요가 없으니까요! 학습 사례가 열 개 있는 경우, 가장 가까운 이웃을 찾기만 하면 나머지 아홉 개는 고려할 필요가 없습니다.
이번에는 반대편 극단으로 가 봅시다. 10-NN 모델을 쓰면 어떻게 될까요? “나와 가장 비슷한 10명의 이웃을 찾고 이들이 가진 타깃의 평균을 내서 예측한다.”가 됩니다. 학습 데이터가 열 개뿐이라면 예측 대상이 될 새로운 사례는 모두 같은 예측 값을 갖게 됩니다. 즉, 모든 이웃의 평균 타깃이 예측 값이 됩니다. 여기에서 우리 예측에는 경계선이 없습니다. 예측 값은 모두 같은 값을 갖습니다. 입력의 특성이 모두 다름에도 같은 값을 예측합니다. 이보다 더 편향된 예측을 하는 방법은 데이터에 관계없이 상수를 예측하는 방법밖에 없습니다.
그림 5-9는 k-NN 모델에 대한 편향 - 분산 상충 관계를 요약합니다. 이웃의 수를 늘리면 편향이 강해지고 분산이 줄어듭니다. 이웃의 수를 낮추면 분산이 커지고 편향이 낮아집니다.
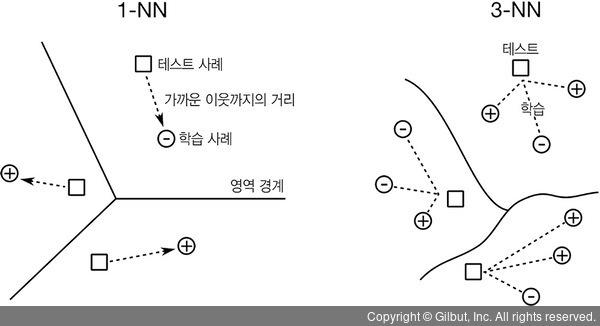
▲ 그림 5-9 k-NN의 편향