7.2.2 K-최근접 이웃 알고리즘
분류 알고리즘은 전체 데이터를 속성별로 분류하는 체계를 만들고 학습한 알고리즘에 따라 새로운 데이터를 분류한다. 대표적인 알고리즘으로 K-최근접 이웃(K-Nearest Neighbor, KNN)과 서포트 벡터 머신(Support Vector Machine, SVM)이 있다. 이 절에서는 머신 러닝 알고리즘에서 쉽다고 여겨지는 K-최근접 이웃 알고리즘을 알아본다.
K-최근접 이웃 알고리즘은 새로운 데이터가 들어오면 기존에 학습한 데이터들과 거리를 비교해 가장 가까운 K개의 데이터 부류로 새로운 데이터를 분류한다.
조류와 포유류를 분류하는 문제를 예로 들어보자. 동물원에 박쥐가 새로 들어왔고, 우리는 박쥐를 분류해야 한다(동물원의 동물들은 머신 러닝에서 훈련용 데이터다).
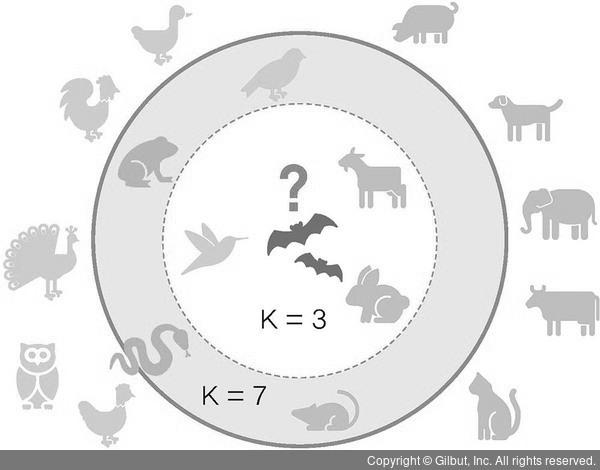
▲ 그림 7-12 박쥐는 포유류인가? 조류인가?
박쥐와 가까운 동물 세 종(K = 3)을 찾아보니 염소, 토끼, 벌새가 나온다. 그중 포유류는 두 종(염소와 토끼)이고, 조류는 한 종(벌새)이다. 그러므로 박쥐는 포유류로 분류한다.
즉, K-최근접 이웃의 알고리즘은 대략 다음과 같다.
1. 새로운 데이터와 기존 데이터 간의 거리를 계산한다.
2. 거리가 짧은 순서대로 정렬한다.
3. 정렬된 결과에서 K개를 가져온다.
4. K개 데이터의 종류를 확인한다.
5. 빈도수가 높은 부류가 새로운 데이터의 유형이다.