첫 번째로 python.find("n")을 하면 문자열에서 처음으로 발견하는 n의 위치인 5를 얻어 와 find 변수에 저장합니다. 그런 다음 python.find("n", find + 1)을 하면 find 변수의 값이 5이므로 결국 이 문장은 python.find("n", 6)을 하는 것과 마찬가지입니다. 이 코드는 문자열에서 n을 찾는데, 찾기 시작하는 위치가 처음이 아니고 인덱스 6부터라는 뜻입니다. 그래서 ‘Python is Amazing’이라는 문자열에서 n을 찾을 때 P부터가 아니라 인덱스 6에 있는 is 바로 앞의 공백부터 찾게 됩니다. 그래서 공백 앞에는 n이 있거나 말거나 그냥 무시하고 지나갑니다. 따라서 결과로 15가 나옵니다. 이는 슬라이싱할 때 a[6:]을 하면 인덱스 6부터 끝까지 문자열을 잘라서 가져오는 것과 비슷합니다.
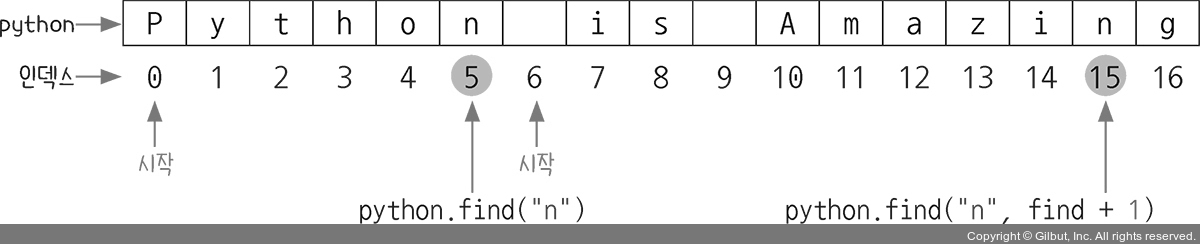
그림 4-4 문자열에서 n의 위치 찾기
index() 함수를 사용해도 결과는 대부분 같습니다. 단, python.find("Java")와 python.index("Java")는 다릅니다. python.find("Java")에서는 문자열에 Java가 없으므로 -1을 출력하고 다음 코드로 넘어갑니다. 하지만 python.index("Java")에서는 문자열에 Java가 없어서 오류를 출력하고 프로그램을 종료합니다. 오류가 발생한 후에 정말 프로그램을 종료하는지 확인하려면 find() 함수와 index() 함수의 순서를 바꿔서 실행해 보세요. 다음처럼 4줄만 출력하고 종료합니다.
|
실행결과 |
5 15 5 ValueError: substring not found |